
Introduction
xlOptimizer implements many variants of Genetic Algorithms [1] for permutation problems. These are included in a solver named PermGA. The permutation problems naturally take the form of deciding on the order in which a sequence of events should occur; for these problems, a natural representation is a permutation of a set of integers. There are two sub-cases of problems; the first includes problems in which the absolute order is important (such as the Job Shop Scheduling problem) while in the second only adjacency is important (a typical example is the Traveling Salesman Problem - TSP) [2].
How does it work?
The algorithm mimics the process of natural selection. A population of candidate solutions is evolved, generation by generation, using techniques inspired by natural evolution such as selection, mutation and crossover.
The evolution starts from a population of randomly generated individuals. In each generation, the fitness of every individual in the population is evaluated. This is a measure of the quality of the solution, and it is depended on the objective function value corresponding to the solution. Next, multiple individuals are stochastically selected from the current population (according to their fitness) to become parents. Their genetic material is recombined, and possibly randomly mutated, to produce offspring and form a new population. The new population is then used in the next iteration of the algorithm. Commonly, the algorithm terminates when either a maximum number of generations has been produced, or a satisfactory fitness level has been reached for the elite (best) member of the population.
Mathematical formulation
Pseudo-code
The PermGA algorithm can be described by the following pseudo-code:
- Initialize randomly the population of individuals (chromosomes).
- Calculate the fitness of each individual in the population.
- Select individuals to form a new population according to each one’s fitness.
- Perform crossover and mutation to form a new population.
- Copy the best (elite) individual to the new population.
- Repeat steps (2–5) until some condition is satisfied.
Encoding
The PermGA so uses permutations of integers, namely from 1 to D, where D is the number of design variables.
Fitness
The fitness of each chromosome is determined by the corresponding objective function value. This objective function is determined by the user. Usually it returns the cost of the candidate solution, and thus it is referred to as the cost function (to be minimized).
Initialization
Initially, solutions are randomly generated to form an initial population. The population size depends on the nature of the problem.
Selection
During each successive generation, a proportion of the existing population is selected to breed a new generation. Individual solutions are selected through a fitness-based process, where fitter solutions (as measured by a fitness function) are typically more likely to be selected. Certain selection methods rate the fitness of each solution and preferentially select the best solutions.
Reproduction: Crossover and mutation
The next step is to generate a new population of solutions using genetic operators: crossover (also called recombination), and/or mutation.
For each new solution to be produced, a pair of "parent" solutions is selected for breeding. Mutation is also stochastically applied to the offspring, which allows the GA to avoid entrapment into local optima and explore new regions of the search space. New parents are selected for each new child, and the process continues until a new population of solutions of appropriate size is generated.
Elitism
Elitism is used in order to ensure that (at least) the best individual of the current generation survives to the next one. Typically one individual, i.e. the best, is transferred as-is to the next generation.
Termination
This generational process is repeated until a termination condition has been reached. Common terminating conditions are:
- A solution is found that satisfies some criteria
- An allocated computation budget is reached
- The highest ranking solution's fitness is reaching or has reached a plateau such that successive iterations no longer produce better results
- Combinations of the above
Options in xlOptimizer add-in
The following options are available in xlOptimizer add-in. Note that whenever an asterisk (*) is indicated in a text field, this means that the field accepts a formula rather than a certain value. The formula is identical to Microsoft Excel's formulas, without the preceding equal sign '='. Also, the function arguments are always separated by comma ',' while the dot '.' is used as a decimal point.
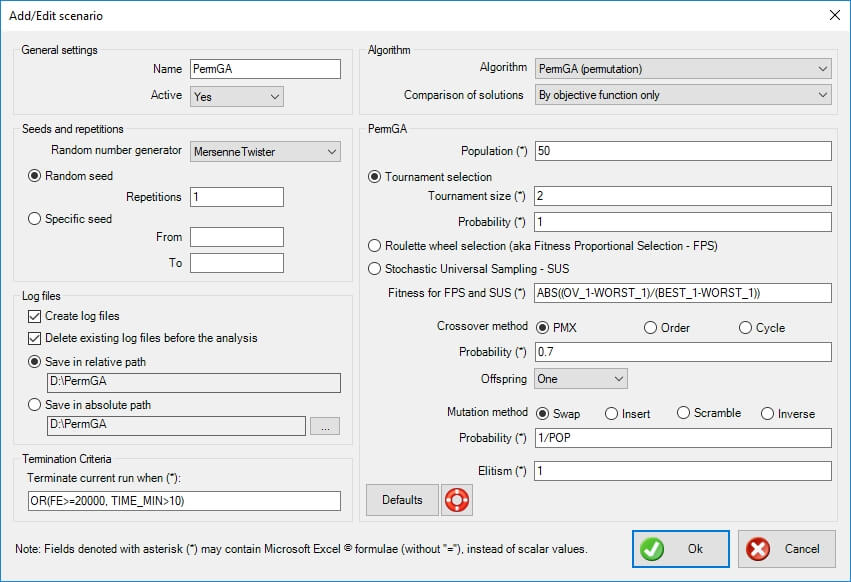
General settings
- Name: the name of the scenario to be run. It should be descriptive but also concise, as a folder with the same name will be (optionally) created, which will hold the log files for further statistical analysis.
- Active: select whether the scenario is active or not. If it is active, it will be run in sequence with the other active scenaria. In the opposite case, it will be ignored. This is very helpful when you experiment with settings.
Seeds and repetitions
Metaheuristic algorithms are based on random number generators. These are algorithms that produce a different sequence of random numbers for each seed they begin with. A seed is just an integer, and a different seed will produce a different evolution history with a different outcome. Robust metaheuristic algorithms should, on average, perform the same no matter what the seed is.
- Random number generator: select the random number generator to be used. The Mersenne Twister is default. The following options are available:
- NumericalRecipes: Numerical Recipes' [3] long period random number generator of L’Ecuyer with Bays-Durham shuffle and added safeguards
- SystemRandomSource: Wraps the .NET System.Random to provide thread-safety
- CryptoRandomSource: Wraps the .NET RNGCryptoServiceProvider
- MersenneTwister: Mersenne Twister 19937 generator
- Xorshift: Multiply-with-carry XOR-shift generator
- Mcg31m1: Multiplicative congruential generator using a modulus of 2^31-1 and a multiplier of 1132489760
- Mcg59: Multiplicative congruential generator using a modulus of 2^59 and a multiplier of 13^13
- WH1982: Wichmann-Hill's 1982 combined multiplicative congruential generator
- WH2006: Wichmann-Hill's 2006 combined multiplicative congruential generator
- Mrg32k3a: 32-bit combined multiple recursive generator with 2 components of order 3
- Palf: Parallel Additive Lagged Fibonacci generator
- Random repetitions: use this option if you wish the program to select random seeds for every run. Also, select the number of repetitions. If you wish to perform a statistical analysis of the results, a sample of 30 runs should be sufficient.
- Specific seed: use this option if you wish to use a selected range of integers as seeds. Note that seeds are usually large negative integers.
Log files
- Create log files: select whether you wish to create a log file for each run. This is imperative if you wish to statistically analyze the results. If you are only interested in the best result out of a certain number of runs, disabling this will increase performance (somewhat).
- Delete existing log files before the analysis: select this option if you want the program to delete all existing (old) log files (with the extension ".output") in the specific folder, before the analysis is performed.
- Save in relative path: select this option to create and use a folder relative to the spreadsheet's path. The name of the folder is controlled in the General Settings > Name.
- Save in absolute path: select this option to create and use a custom folder. Press the corresponding button with the ellipses "..." to select the folder.
Termination criteria
Each scenario needs a specific set of termination criteria. You can use an excel-like expression with the following variables (case insensitive):
- 'BEST_1', 'BEST_2', etc represent the best value of the objective function 1, 2, etc in the population.
- 'AVERAGE_1', 'AVERAGE_2', etc represent the average value of the objective function 1, 2, etc in the population.
- 'WORST_1', 'WORST_2', etc represent the worst value of the objective function 1, 2, etc in the population.
- 'MIN_1', 'MIN_2', etc represent the minimum value of the objective function 1, 2, etc in the population.
- 'MAX_1', 'MAX_2', etc represent the maximum value of the objective function 1, 2, etc in the population.
- 'FE' represents the function evaluations so far.
- 'TIME_MIN' represents the elapsed time (in minutes) since the beginning of the run.
- 'BEST_REMAINS_FE' represents the number of the last function evaluations during which the best solution has not been improved.
The default formula is 'OR(FE>=20000, TIME_MIN>10)' which means that the run is terminated when the number of function evaluations is more than 20000 or the run has lasted more than 10 minutes.
Algorithm
- Algorithm: select the algorithm to be used in the specific scenario. In this case 'PermGA (permutation)' is selected.
- Comparison of solutions: select whether feasibility (i.e. the fact that a specific solution does not violate any constraints) is used in the comparison between solutions. The following options are available:
- By objective function only: feasibility is ignored, and only the objective function (potentially including penalties from constraint violations) is used to compare solutions.
- By objective function and feasibility: the objective function (potentially including penalties from constraint violations) is used to compare solutions, but in the end, a feasible solution is always preferred to an infeasible one.
PermGA
The following options are specific to PermGA (permutation).
Population
Enter a formula for the calculation of the population size. You can use an excel-like expression with the following variables (case insensitive):
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
The default setting is '50', but larger population is required if the dimensionality of the problem is large.
Selection
Select a method for the selection of individuals for reproduction. Tournament selection is default, because it allows mediocre solutions to survive and evolve, and thus maintains the population's diversity, which is critical in Genetic Algorithms. The following options are available:
- Tournament selection: a tournament is performed between k individuals, and the best is selected with a probability p.
- The tournament size k is determined by a formula. The default setting is '2', meaning a tournament of two individuals is performed. You can use an excel-like expression with the following variables (case insensitive):
- 'POP' represents the population size.
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
- The probability p is determined by a formula. The default setting is '1', meaning the best of the tournament is always selected (i.e. with a probability 100%). You can use an excel-like expression with the following variables (case insensitive):
- 'POP' represents the population size.
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
- The tournament size k is determined by a formula. The default setting is '2', meaning a tournament of two individuals is performed. You can use an excel-like expression with the following variables (case insensitive):
- Roulette Wheel Selection (also known as Fitness Proportional Selection): a biased roulette wheel is used to select individuals. In order to determine the bias for each solution in the wheel (i.e. the size of the wedge), a fitness function is used which normalizes and smooths the differences between individuals in a population. This is critical in Genetic Algorithms because a super-individual in a specific generation will quickly dominate the population and lead to premature convergence.
- Stochastic Universal Sampling: an improvement of the Roulette Wheel Selection with no bias and minimal spread.
For the Roulette Wheel Selection and Stochastic Universal Sampling, a fitness is defined. You can use an excel-like expression with the following variables (case insensitive):
- 'POP' represents the population size.
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
- 'GEN' represents the current generation (0 is the initial random generation).
- 'OV_1', 'OV_2', 'OV_3', etc represent the objective value of function 1, 2, 3, etc
- 'MIN_1', 'MIN_2', etc represent the minimum value of the objective function 1, 2, etc in the population.
- 'MAX_1', 'MAX_2', etc represent the maximum value of the objective function 1, 2, etc in the population.
- 'BEST_1', 'BEST_2', etc represent the best value of the objective function 1, 2, etc in the population.
- 'AVERAGE_1', 'AVERAGE_2', etc represent the average value of the objective function 1, 2, etc in the population.
- 'WORST_1', 'WORST_2', etc represent the worst value of the objective function 1, 2, etc in the population.
The default setting is 'ABS((OV_1-WORST_1)/(BEST_1-WORST_1))'.
Crossover
Crossover is a genetic operator used to vary the programming of a chromosome or chromosomes from one generation to the next. The crossover operators for permutation problems differ from the ones of simple Genetic Algorithms due to the special nature of the problem. Select the appropriate crossover method. The following options are available:
- PMX: partially mapped crossover
- Order crossover
- Cycle crossover
Usually PMX or Order crossover is used for adjacency problems. Cycle crossover is used for problems where the absolute position in the string is important. The crossover methods are described in detail in [2].
For all options, the crossover is applied with a certain probability. In the opposite case, the individual is copied as-is in the next generation. The crossover probability is evaluated with a formula. The default setting is '0.7'. You can use an excel-like expression with the following variables (case insensitive):
- 'POP' represents the population size.
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
- 'GEN' represents the current generation (0 is the initial random generation).
'MIN_1', 'MIN_2', etc represent the minimum value of the objective function 1, 2, etc in the population. - 'MAX_1', 'MAX_2', etc represent the maximum value of the objective function 1, 2, etc in the population.
- 'BEST_1', 'BEST_2', etc represent the best value of the objective function 1, 2, etc in the population.
- 'AVERAGE_1', 'AVERAGE_2', etc represent the average value of the objective function 1, 2, etc in the population.
- 'WORST_1', 'WORST_2', etc represent the worst value of the objective function 1, 2, etc in the population.
Also, there is the option of creating either one or two offspring from a specific pair of father and mother chromosomes.
Mutation
Mutation is a genetic operator used to maintain genetic diversity from one generation of a population of genetic algorithm chromosomes to the next. Again, the mutation operators for permutation problems differ from the corresponding operators for simple Genetic Algorithms due to the special nature of the problem. Select the appropriate settings for the mutation of individuals. The following options are available:
- Swap
- Insert
- Scramble
- Inverse
The mutation methods are described in detail in [2]. The probability for the application of mutation is given by a formula. The default setting is '1/POP' (note: the random number generator is invoked POP times during the analysis of a population, thus 1/POP means, on average, one jump mutation for the whole population). You can use an excel-like expression with the following variables (case insensitive):
- 'POP' represents the population size.
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
- 'GEN' represents the current generation (0 is the initial random generation).
- 'MIN_1', 'MIN_2', etc represent the minimum value of the objective function 1, 2, etc in the population.
- 'MAX_1', 'MAX_2', etc represent the maximum value of the objective function 1, 2, etc in the population.
- 'BEST_1', 'BEST_2', etc represent the best value of the objective function 1, 2, etc in the population.
- 'AVERAGE_1', 'AVERAGE_2', etc represent the average value of the objective function 1, 2, etc in the population.
- 'WORST_1', 'WORST_2', etc represent the worst value of the objective function 1, 2, etc in the population.
Elitism
Elitism is a genetic operator which copies a number of elite (best) individuals from one generation to the next. This operator is almost always used, as it improves performance. Select the appropriate formula for the elitism. The default value is '1', which means that the single best individual is copied to the next generation unaltered. You can use an excel-like expression with the following variables (case insensitive):
- 'POP' represents the population size.
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
- 'GEN' represents the current generation (0 is the initial random generation).
- 'MIN_1', 'MIN_2', etc represent the minimum value of the objective function 1, 2, etc in the population.
- 'MAX_1', 'MAX_2', etc represent the maximum value of the objective function 1, 2, etc in the population.
- 'BEST_1', 'BEST_2', etc represent the best value of the objective function 1, 2, etc in the population.
- 'AVERAGE_1', 'AVERAGE_2', etc represent the average value of the objective function 1, 2, etc in the population.
- 'WORST_1', 'WORST_2', etc represent the worst value of the objective function 1, 2, etc in the population.
References
[1] Holland, J.H. (1975) Adaptation in Natural and Artificial Systems, The University of Michigan Press, Ann Arbor.
[2] Eiben, A.E., Smith, J.E. (2003) Introduction to Evolutionary Computing. Springer, New York.
[3] Press, W.H., Teukolsky, S.A., Vetterling, W.T. and Flannery, B.P. (2002) Numerical recipes in C++: the art of scientific computing. Cambridge University Press.