
Introduction
xlOptimizer implements Simulated Annealing as a stand-alone algorithm. The name and inspiration of the algorithm come from annealing in metallurgy, a technique involving heating and controlled cooling of a material to increase the size of its crystals and reduce their defects.
How does it work?
The implementation of the Simulated Annealing, outlined below, is based on the work of Balling [1] . The algorithm begins with an initial design. This can be the current solution in the worksheet, or a random solution based on the lower and upper bounds of each design variable. This is followed by the creation of a certain number of additional random designs (selected by the user), which are checked against the current design. The best of these designs becomes the current design. This preliminary loop is done in order to avoid the possibility that the starting point for the optimization is too poor. Following the selection of an appropriate cooling schedule, the current design is subjected to small perturbations to create a candidate design. Whenever the candidate design is better than the current one, it replaces it with probability of 1. For a minimization problem, this is expressed mathematically as:
$$\Delta f = f\left( {{{\bf{x}}_a}} \right) - f\left( {{{\bf{x}}_c}} \right) \le 0 \Rightarrow P\left( {{{\bf{x}}_a} \to {{\bf{x}}_c}} \right) = 1$$
If it is worse, it still replaces it with a probability given by:
$\Delta f = f\left( {{{\bf{x}}_a}} \right) - f\left( {{{\bf{x}}_c}} \right) > 0 \Rightarrow P\left( {{{\bf{x}}_a} \to {{\bf{x}}_c}} \right) = {e^{ - {{\Delta f} \over {K{\rm{ }}{t_c}}}}} \le 1$
where, K = Boltzman parameter and tc = current system temperature, corresponding to cooling cycle c. The Boltzman parameter is not kept constant during optimization. Instead, it is updated prior to using the previous equation as follows:
$${K_{{N_a} + 1}} = {{{K_{{N_a}}}{N_a} + \left| {\Delta f} \right|} \over {{N_a} + 1}}$$
where, Na = number of accepted designs so far, and KNa previous Boltzman parameter. Initially, Na = 0 and K0 = 1. The starting and final system temperatures are given by:
${t_s} = - {1 \over {\ln \left( {{P_s}} \right)}},{\rm{ }}{t_f} = - {1 \over {\ln \left( {{P_f}} \right)}}$
where, Ps and Pf = starting and final probability of acceptance, respectively. The temperature is reduced gradually in Nc cooling cycles, as follows:
${t_{c + 1}} = cf \times {t_c}$
where, cf = cooling factor, given by:
$cf = {\left( {{{{t_f}} \over {{t_s}}}} \right)^{{1 \over {{N_c} - 1}}}}$
At each cooling cycle, a number of inner loops of perturbation/improvement of the current design is executed. For each loop, an array of integers representing the design variables (1 to D) is shuffled. According to the sequence indicated in the shuffled array, each design variable is in turn perturbed to form the candidate design according to:
${x_{ia}} = {x_{ic}} + \left( {2r - 1} \right){d_i}$
where, di = magnitude of perturbation of variable i. Note that the side constraints of design variables are re-enforced after using the previous equation. It has been observed that inner loops are more important at low temperatures. For this reason, the repetitions I of the inner loop are not kept constant but instead they are determined as follows:
$I = round\left( {{I_s} + \left( {{I_f} - {I_s}} \right){{{t_c} - {t_s}} \over {{t_f} - {t_s}}}} \right)$
where, Is and If = starting and final number of repetitions of inner loops, respectively. Note that in Simulated Annealing the current design is occasionally replaced by a poorer design. This means that even if a better design replaces the current design, it may not be the best ever design. xlOptimizer, however, keeps of the best design found so far during the optimization process.
The driving force of the algorithm is based on three pillars: (i) high temperatures observed at the beginning of the cooling cycle encourage acceptance of poorer designs (ii) poorer designs with small have higher probability of acceptance than poorer designs with large (iii) the temperature is gradually decreased during the cooling process and, thus, the probability of accepting a poorer design is reduced accordingly. This gradually shifts the focus from exploration of the search space to exploitation of the most promising solution.
Options in xlOptimizer add-in
The following options are available in xlOptimizer add-in. Note that whenever an asterisk (*) is indicated in a text field, this means that the field accepts a formula rather than a certain value. The formula is identical to Microsoft Excel's formulas, without the preceding equal sign '='. Also, the function arguments are always separated by comma ',' while the dot '.' is used as a decimal point.
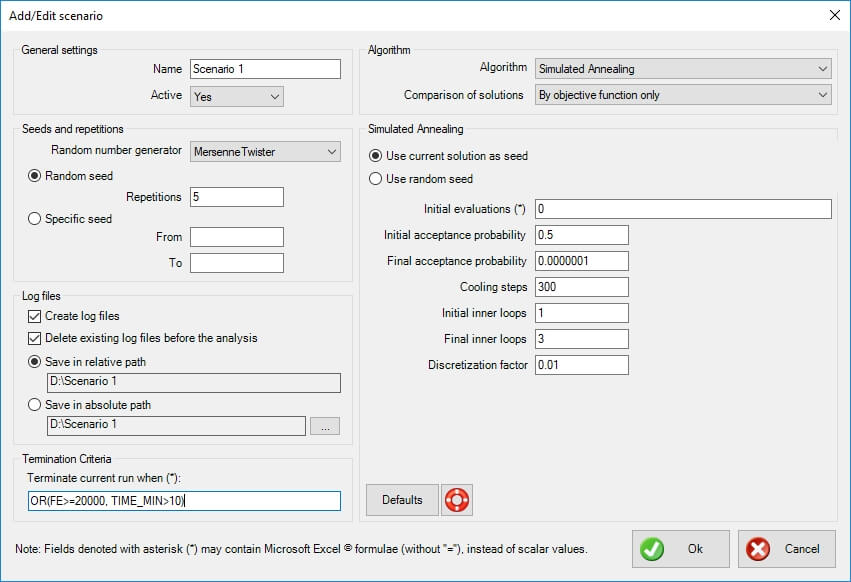
General settings
- Name: the name of the scenario to be run. It should be descriptive but also concise, as a folder with the same name will be (optionally) created, which will hold the log files for further statistical analysis.
- Active: select whether the scenario is active or not. If it is active, it will be run in sequence with the other active scenaria. In the opposite case, it will be ignored. This is very helpful when you experiment with settings.
Seeds and repetitions
Metaheuristic algorithms are based on random number generators. These are algorithms that produce a different sequence of random numbers for each seed they begin with. A seed is just an integer, and a different seed will produce a different evolution history with a different outcome. Robust metaheuristic algorithms should, on average, perform the same no matter what the seed is.
- Random number generator: select the random number generator to be used. The Mersenne Twister is default. The following options are available:
- NumericalRecipes: Numerical Recipes' long period random number generator of L’Ecuyer with Bays-Durham shuffle and added safeguards
- SystemRandomSource: Wraps the .NET System.Random to provide thread-safety
- CryptoRandomSource: Wraps the .NET RNGCryptoServiceProvider
- MersenneTwister: Mersenne Twister 19937 generator
- Xorshift: Multiply-with-carry XOR-shift generator
- Mcg31m1: Multiplicative congruential generator using a modulus of 2^31-1 and a multiplier of 1132489760
- Mcg59: Multiplicative congruential generator using a modulus of 2^59 and a multiplier of 13^13
- WH1982: Wichmann-Hill's 1982 combined multiplicative congruential generator
- WH2006: Wichmann-Hill's 2006 combined multiplicative congruential generator
- Mrg32k3a: 32-bit combined multiple recursive generator with 2 components of order 3
- Palf: Parallel Additive Lagged Fibonacci generator
- Random repetitions: use this option if you wish the program to select random seeds for every run. Also, select the number of repetitions. If you wish to perform a statistical analysis of the results, a sample of 30 runs should be sufficient.
- Specific seed: use this option if you wish to use a selected range of integers as seeds. Note that seeds are usually large negative integers.
Log files
- Create log files: select whether you wish to create a log file for each run. This is imperative if you wish to statistically analyze the results. If you are only interested in the best result out of a certain number of runs, disabling this will increase performance (somewhat).
- Delete existing log files before the analysis: select this option if you want the program to delete all existing (old) log files (with the extension ".output") in the specific folder, before the analysis is performed.
- Save in relative path: select this option to create and use a folder relative to the spreadsheet's path. The name of the folder is controlled in the General Settings > Name.
- Save in absolute path: select this option to create and use a custom folder. Press the corresponding button with the ellipses "..." to select the folder.
Termination criteria
Each scenario needs a specific set of termination criteria. You can use an excel-like expression with the following variables (case insensitive):
- 'BEST_1', 'BEST_2', etc represent the best value of the objective function 1, 2, etc in the population.
- 'AVERAGE_1', 'AVERAGE_2', etc represent the average value of the objective function 1, 2, etc in the population.
- 'WORST_1', 'WORST_2', etc represent the worst value of the objective function 1, 2, etc in the population.
- 'MIN_1', 'MIN_2', etc represent the minimum value of the objective function 1, 2, etc in the population.
- 'MAX_1', 'MAX_2', etc represent the maximum value of the objective function 1, 2, etc in the population.
- 'FE' represents the function evaluations so far.
- 'TIME_MIN' represents the elapsed time (in minutes) since the beginning of the run.
- 'BEST_REMAINS_FE' represents the number of the last function evaluations during which the best solution has not been improved.
The default formula is 'OR(FE>=20000, TIME_MIN>10)' which means that the run is terminated when the number of function evaluations is more than 20000 or the run has lasted more than 10 minutes.
Algorithm
- Algorithm: select the algorithm to be used in the specific scenario. In this case 'Simulated Annealing' is selected.
- Comparison of solutions: select whether feasibility (i.e. the fact that a specific solution does not violate any constraints) is used in the comparison between solutions. The following options are available:
- By objective function only: feasibility is ignored, and only the objective function (potentially including penalties from constraint violations) is used to compare solutions.
- By objective function and feasibility: the objective function (potentially including penalties from constraint violations) is used to compare solutions, but in the end, a feasible solution is always preferred to an infeasible one.
Simulated Annealing
The following options are specific to Simulated Annealing.
- Use current solution as seed. This will load the current solution from the spreadsheet and use it as seed in Simulated Annealing. Note that the boundaries of each design variable is imposed again.
- Use random seed. This will produce a random solution as seed (i.e. initial solution to be improved).
Initial evaluations
Enter a formula for the calculation of the initial random designs. You can use an excel-like expression with the following variables (case insensitive):
- 'VARS' represents the number of variables (i.e. the dimensionality of the problem).
The default setting is 'VARS', which is a good choice for most problems.
Initial acceptance probability
Enter the initial acceptance probability. A value in the range 0.5 - 0.9 is common. The default value is 0.5.
Final acceptance probability
Enter the final acceptance probability. This is a small number, so that the probability that a worse design substitutes the current one gets smaller as optimization progresses. A value of 1e-07 is default.
Cooling steps
Enter the number of cooling steps. This must be grater than 1. The default value is 300.
Initial inner loops
Enter the initial inner loops. Default value is 1.
Final inner loops
Enter the final inner loops. Default value is 3.
Discretization factor
Enter the discretization factor df. The perturbation magnitude di of design variable i is evaluated as (upper_boundi - lower_boundi)*df. Default value is 0.01 (1%).
References
[1] Balling, R. J. (1991) ‘Optimal steel frame design by Simulated Annealing’, Journal of Structural Engineering, 117(6), pp. 1780–1795. doi: 10.1061/(ASCE)0733-9445(1991)117:6(1780)..